MongoDB — Complete Guide
MongoDB is a source-available cross-platform document-oriented database program. Classified as a NoSQL database program, MongoDB uses JSON-like documents with optional schemas. MongoDB is developed by MongoDB Inc. MongoDB is a general purpose, document-based, distributed database built for modern application developers and for the cloud era. MongoDB is written in C++.
For installation refer: Install MongoDB — MongoDB Manual
To make data persistent, we store it in a file, which is then stored in a folder, which is then stored in hard-disk storage. This is referred to as the File System. File system controls how data is stored and retrieved.
What is NoSQL?
Databases can be considered as one of the important component entity for technology and applications. Data need to be stored in a specific structure and format to retrieve it whenever required. But, there are situations where data are not always in a structured format, i.e., their schemas are not rigid.
NoSQL can be defined as an approach to database designing, which holds a vast diversity of data such as key-value, multimedia, document, columnar, graph formats, external files, etc. NoSQL is purposefully developed for handling specific data models having flexible schemas to build modern applications.
NoSQL is famous for its high functionality, ease of development with a performance at scale. Because of such diverse data handling feature, NoSQL is called a non-relational database. It does not follow the rules of Relational Database Management Systems (RDBMS), and hence do not use traditional SQL statements to query your data. Some famous examples are MongoDB, Neo4J, HyperGraphDB, etc.
Database
Database is a physical container for collections. Each database gets its own set of files on the file system. A single MongoDB server typically has multiple databases.
Collection
Collection is a group of MongoDB documents. It is the equivalent of an RDBMS table. A collection exists within a single database. Collections do not enforce a schema. Documents within a collection can have different fields. Typically, all documents in a collection are of similar or related purpose.
Document
A document is a set of key-value pairs. Documents have dynamic schema. Dynamic schema means that documents in the same collection do not need to have the same set of fields or structure, and common fields in a collection’s documents may hold different types of data.
Types of NoSQL Databases
NoSQL databases usually fall under any one of these four categories:
- Key-value stores: is the most straightforward type where every item of your database gets stored in the form of an attribute name (i.e., “key”) along with the value.
- Wide-column stores: accumulate data collectively as a column rather than rows which are optimized for querying big datasets.
- Document databases: couple every key with a composite data structure termed as a document. These documents hold a lot of different key-value pairs, as well as key-array pairs or sometimes nested documents.
- Graph databases: are used for storing information about networks, like social connections.
Difference Between NoSQL and SQL
Here is the list of comparisons between both the DBMS:
- SQL databases are mainly coming under Relational Databases (RDBMS) whereas NoSQL databases mostly come under non-relational or distributed database.
- SQL databases are table-oriented databases, whereas NoSQL databases document-oriented have key-value pairs or wide-column stores or graph databases.
- SQL databases have a predefined or static schema that is rigid, whereas NoSQL databases have dynamic or flexible schema to handle unstructured data.
- SQL is used to store structured data, whereas NoSQL is used to store structured as well as unstructured data.
- SQL databases can be considered as vertically scalable, but NoSQL databases are considered horizontally scalable.
- Scaling of SQL databases is done by mounting the horse-power of your hardware. But, scaling of NoSQL databases is calculated by mounting the databases servers for reducing the load.
- Examples of SQL databases: MySql, Sqlite, Oracle, Postgres SQL, and MS-SQL. Examples of NoSQL databases: BigTable, MongoDB, Redis, Cassandra, RavenDb, Hbase, CouchDB and Neo4j
- When your queries are complex SQL databases are a good fit for the intensive environment, and NoSQL databases are not an excellent fit for complex queries. Queries of NoSQL are not that powerful as compared to SQL query language.
- SQL databases need vertical scalability, i.e., excess of load can be managed by increasing the CPU, SSD, RAM, GPU, etc., on your server. In the case of NoSQL databases, they horizontally scalable, i.e., the addition of more servers will ease out the load management thing to handle.
MongoDB Features
- Each database contains collections which in turn contains documents. Each document can be different with a varying number of fields. The size and content of each document can be different from each other.
- The document structure is more in line with how developers construct their classes and objects in their respective programming languages. Developers will often say that their classes are not rows and columns but have a clear structure with key-value pairs.
- The rows (or documents as called in MongoDB) doesn’t need to have a schema defined beforehand. Instead, the fields can be created on the fly.
- The data model available within MongoDB allows you to represent hierarchical relationships, to store arrays, and other more complex structures more easily.
Advantages of MongoDB over RDBMS
- Schema less − MongoDB is a document database in which one collection holds different documents. Number of fields, content and size of the document can differ from one document to another.
- Structure of a single object is clear.
- No complex joins.
- Deep query-ability. MongoDB supports dynamic queries on documents using a document-based query language that’s nearly as powerful as SQL.
- Tuning.
- Ease of scale-out − MongoDB is easy to scale.
- Conversion/mapping of application objects to database objects not needed.
- Uses internal memory for storing the (windowed) working set, enabling faster access of data.
Where to Use MongoDB?
- Big Data
- Content Management and Delivery
- Mobile and Social Infrastructure
- User Data Management
- Data Hub
Key Components of MongoDB Architecture
Below are a few of the common terms used in MongoDB
- _id — This is a field required in every MongoDB document. The _id field represents a unique value in the MongoDB document. The _id field is like the document’s primary key. If you create a new document without an _id field, MongoDB will automatically create the field. So for example, if we see the example of the above customer table, Mongo DB will add a 24 digit unique identifier to each document in the collection.
- Collection — This is a grouping of MongoDB documents. A collection is the equivalent of a table which is created in any other RDMS such as Oracle or MS SQL. A collection exists within a single database. As seen from the introduction collections don’t enforce any sort of structure.
- Cursor — This is a pointer to the result set of a query. Clients can iterate through a cursor to retrieve results.
- Database — This is a container for collections like in RDMS wherein it is a container for tables. Each database gets its own set of files on the file system. A MongoDB server can store multiple databases.
- Document — A record in a MongoDB collection is basically called a document. The document, in turn, will consist of field name and values.
- Field — A name-value pair in a document. A document has zero or more fields. Fields are analogous to columns in relational databases.
- The following diagram shows an example of Fields with Key value pairs. So in the example below CustomerID and 11 is one of the key value pair’s defined in the document.

7. JSON — This is known as JavaScript Object Notation. This is a human-readable, plain text format for expressing structured data. JSON is currently supported in many programming languages.
MongoDB CRUD Operations
CRUD operations create, read, update, and delete documents.
Create Operations
Create or insert operations add new documents to a collection. If the collection does not currently exist, insert operations will create the collection.
MongoDB provides the following methods to insert documents into a collection:
db.collection.insertOne()New in version 3.2db.collection.insertMany()New in version 3.2
In MongoDB, insert operations target a single collection. All write operations in MongoDB are atomic on the level of a single document.
Read Operations
Read operations retrieve documents from a collection; i.e. query a collection for documents. MongoDB provides the following methods to read documents from a collection:
db.collection.find()
You can specify query filters or criteria that identify the documents to retur
Update Operations
Update operations modify existing documents in a collection. MongoDB provides the following methods to update documents of a collection:
db.collection.updateOne()New in version 3.2db.collection.updateMany()New in version 3.2db.collection.replaceOne()New in version 3.2
In MongoDB, update operations target a single collection. All write operations in MongoDB are atomic on the level of a single document.
You can specify criteria, or filters, that identify the documents to update. These filters use the same syntax as read operations.
Delete Operations
Delete operations remove documents from a collection. MongoDB provides the following methods to delete documents of a collection:
db.collection.deleteOne()New in version 3.2db.collection.deleteMany()New in version 3.2
In MongoDB, delete operations target a single collection. All write operations in MongoDB are atomic on the level of a single document.
You can specify criteria, or filters, that identify the documents to remove. These filters use the same syntax as read operations.
Installing Compass for MongoDB
MongoDB Compass is a great GUI tool for inspecting and interacting with the data in your MongoDB database. It’s free, and easy to set up.
- Go to the download page for MongoDB Compass, choose “Community Edition Stable” from the dropdown menu, and click “Download”

- Open the .dmg and follow the instructions (drag the MongoDB Compass Community app into the Applications folder)
- Open MongoDB Compass Community from the Applications folder and agree to the license agreement. Feel free to follow through the small tutorial they provide.
- When you get to the “Connect to Host” page, fill in the following pieces of information:
Hostname: localhost
Port: 27017
Favorite Name: Local MongoDB(Everything else you can skip for now)
4. Click “Save Favorite”, then “Connect”
You should now be able to see a list of the databases you have created on your machine so far. Clicking in to one will show the list of collections in the database. Clicking the name of the collection will open you to a view where you can see all the documents in that collection.
Hovering over the documents, you’ll be able to see a small menu on the right, where you can Edit, Copy, Clone, or Delete any given document.
MongoDB — Import Data
MongoDB provides the mongoimport utility that can be used to import JSON, CSV, or TSV files into a MongoDB database.
mongoimport is located in the bin directory (eg, /mongodb/bin or wherever you installed it).
To import data, open a new Terminal/Command Prompt window and enter mongoimport followed by parameters such as database name, collection name, source file name, etc.
Import JSON File
Here’s an example of running mongoimport to import a JSON file.
mongoimport --db music --file /data/dump/music/artists.jsonIntegrating MongoDB with Python Using PyMongo
MongoDB provides drivers and tools for interacting with a MongoDB datastore using various programming languages including Python, JavaScript, Java, Go, and C#, among others.
PyMongo is the official MongoDB driver for Python, and we will use it to create a simple script that we will use to manipulate data stored in our SeriesDB database.
Connecting to MongoDB
First, we import pymongo in our mongo_db_script.py and create a client connected to our locally running instance of MongoDB:
import pymongo# Create the client
client = MongoClient('localhost', 27017)# Connect to our database
db = client['SeriesDB']# Fetch our series collection
series_collection = db['series']
Indexes
Indexes support the efficient execution of queries in MongoDB. Without indexes, MongoDB must perform a collection scan, i.e. scan every document in a collection, to select those documents that match the query statement. If an appropriate index exists for a query, MongoDB can use the index to limit the number of documents it must inspect.
What is Primary Key in MongoDB?
In MongoDB, _id field as the primary key for the collection so that each document can be uniquely identified in the collection. The _id field contains a unique ObjectID value.
By default when inserting documents in the collection, if you don’t add a field name with the _id in the field name, then MongoDB will automatically add an Object id field.
Sharding
Sharding is the process of storing data records across multiple machines and it is MongoDB’s approach to meeting the demands of data growth. As the size of the data increases, a single machine may not be sufficient to store the data nor provide an acceptable read and write throughput. Sharding solves the problem with horizontal scaling. With sharding, you add more machines to support data growth and the demands of read and write operations.
What are shards?
There are database situations where the data sets in MongoDB will grow so massive, that MongoDB statements, operations, and queries against such large data sets can cause a tremendous amount of CPU utilization on that particular server. Such situations can be tacked in MongoDB using this concept of “sharding”, where the data sets are split across numerous instances of MongoDB. That extensive collection of data sets can be actually split across several small-sized collections called “Shards”. But, logically, all the shards perform the work as a single collection.
Ways of Addressing System Growth
There is a parallel concept that is implemented for understanding sharding. System growth or scaling (which is used to increase the efficiency and working power of a system) can be addressed in 2 different ways. These are -
- Vertical Scaling engages escalating the ability of a single server by making use of a more powerful CPU, where additional RAMs are incorporated, as well as the amount of storage has also increased. Restrictions
- Horizontal Scaling engages segregating the data set of a single system as well as its workload over several servers, where similar servers are interconnected for increasing the capacity as per requirement. Here each server may not have high speed or capacity, but all of them together can handle the workload and provide efficient work than that of a single high-speed server.
Hence, sharding uses the concept of horizontal scaling to support the processing of large data sets.
Why Sharding?
- In replication, all writes go to master node
- Latency sensitive queries still go to master
- Single replica set has limitation of 12 nodes
- Memory can’t be large enough when active dataset is big
- Local disk is not big enough
- Vertical scaling is too expensive
Sharding in MongoDB
The following diagram shows the Sharding in MongoDB using sharded cluster.
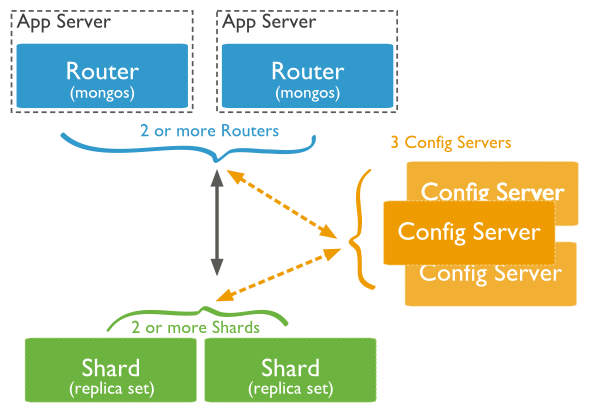
In the following diagram, there are three main components −
- Shards − Shards are used to store data. They provide high availability and data consistency. In production environment, each shard is a separate replica set.
- Config Servers − Config servers store the cluster’s metadata. This data contains a mapping of the cluster’s data set to the shards. The query router uses this metadata to target operations to specific shards. In production environment, sharded clusters have exactly 3 config servers.
- Query Routers − Query routers are basically mongo instances, interface with client applications and direct operations to the appropriate shard. The query router processes and targets the operations to shards and then returns results to the clients. A sharded cluster can contain more than one query router to divide the client request load. A client sends requests to one query router. Generally, a sharded cluster have many query routers.
Replication in MongoDB
A replica set is a group of mongod instances that maintain the same data set. A replica set contains several data bearing nodes and optionally one arbiter node. Of the data bearing nodes, one and only one member is deemed the primary node, while the other nodes are deemed secondary nodes.

How Replication Works in MongoDB
MongoDB achieves replication by the use of replica set. A replica set is a group of mongod instances that host the same data set. In a replica, one node is primary node that receives all write operations. All other instances, such as secondaries, apply operations from the primary so that they have the same data set. Replica set can have only one primary node.
- Replica set is a group of two or more nodes (generally minimum 3 nodes are required).
- In a replica set, one node is primary node and remaining nodes are secondary.
- All data replicates from primary to secondary node.
- At the time of automatic failover or maintenance, election establishes for primary and a new primary node is elected.
- After the recovery of failed node, it again join the replica set and works as a secondary node.
Set Up a Replica Set
We will convert standalone MongoDB instance to a replica set. To convert to replica set, following are the steps −
- Shutdown already running MongoDB server
- Start the MongoDB server by specifying — replSet option. Following is the basic syntax of — replSet −
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"Example
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0- It will start a mongod instance with the name rs0, on port 27017.
- Now start the command prompt and connect to this mongod instance.
- In Mongo client, issue the command rs.initiate() to initiate a new replica set.
- To check the replica set configuration, issue the command rs.conf(). To check the status of replica set issue the command rs.status().
Add Members to Replica Set
To add members to replica set, start mongod instances on multiple machines. Now start a mongo client and issue a command rs.add().
The basic syntax of rs.add() command is as follows −
>rs.add(HOST_NAME:PORT)Explain Results
To return information on query plans and execution statistics of the query plans, MongoDB provides:
- the
db.collection.explain()method, - the
cursor.explain()method, and - the
explaincommand.
Each stage passes its results (i.e. documents or index keys) to the parent node. The leaf nodes access the collection or the indices. The internal nodes manipulate the documents or the index keys that result from the child nodes. The root node is the final stage from which MongoDB derives the result set.
- Stages are descriptive of the operation; e.g.
COLLSCANfor a collection scanIXSCANfor scanning index keysFETCHfor retrieving documentsSHARD_MERGEfor merging results from shardsSHARDING_FILTERfor filtering out orphan documents from shards
MongoDB — Compound Indexes
MongoDB provides indexing for efficient execution of queries without indexes MongoDB has to search every document to match the query which is highly inefficient. Indexes are easy to traverse and store sorted documents according to the specified fields. Unlike single field index in which indexing is done on a single field, Compound Indexes does indexing on multiple fields of the document either in ascending or descending order i.e. it will sort the data of one field, and then inside that it will sort the data of another field. Or in other words, compound indexes are those indexes where a single index field contains references to multiple fields. In MongoDB, the compound index can contain a single hashed index field, if a field contains more than one hashed index field then MongoDB will give an error.
How to create a compound Index?
In MongoDB, we can create compound index using createIndex() method.
Syntax: db.collection.createIndex({<field1>: <type1>, <field2>: <type2>, …})
Here <type> represents the value of the field in the index specification describes the kind of index for that field. For example, a value 1 for indexing in ascending order or value -1 for indexing in descending order.
Aggregation Pipeline in MongoDB
The aggregation pipeline is a framework for data aggregation modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results. For example:
db.orders.aggregate([ { $match: { status: "A" } }, { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }])First Stage: The $match stage filters the documents by the status field and passes to the next stage those documents that have status equal to "A".
Second Stage: The $group stage groups the documents by the cust_id field to calculate the sum of the amount for each unique cust_id.
Pipeline
The MongoDB aggregation pipeline consists of stages. Each stage transforms the documents as they pass through the pipeline. Pipeline stages do not need to produce one output document for every input document. For example, some stages may generate new documents or filter out documents.
Pipeline stages can appear multiple times in the pipeline with the exception of $out, $merge, and $geoNear stages. For a list of all available stages, see Aggregation Pipeline Stages.
MongoDB provides the db.collection.aggregate() method in the mongo shell and the aggregate command to run the aggregation pipeline.
Following are the possible stages in aggregation framework −
- $project − Used to select some specific fields from a collection.
- $match − This is a filtering operation and thus this can reduce the amount of documents that are given as input to the next stage.
- $group − This does the actual aggregation as discussed above.
- $sort − Sorts the documents.
- $skip − With this, it is possible to skip forward in the list of documents for a given amount of documents.
- $limit − This limits the amount of documents to look at, by the given number starting from the current positions.
- $unwind − This is used to unwind document that are using arrays. When using an array, the data is kind of pre-joined and this operation will be undone with this to have individual documents again. Thus with this stage we will increase the amount of documents for the next stage.
Mongo Router Program in MongoDB
Mongo Router in MongoDB is a router type of program which is present in the master node of cluster. The metadata of the data in every slave node is contained there. When a customer query exists for the data the query to that specific slave node containing the data will be redirected.
Referencing Model in MongoDB
Referencing model is a kind of architectural design for storing the data into multiple documents. Here the data is referenced to its cursor so that the update operations can be easily done.
MongoDB Atlas
MongoDB Atlas is a fully-managed cloud database developed by the same people that build MongoDB. Atlas handles all the complexity of deploying, managing, and healing your deployments on the cloud service provider of your choice (AWS, Azure, and GCP). MongoDB Atlas is the core database at the center of the MongoDB Cloud. MongoDB Atlas allows developers to get started right away in any of the public clouds and easily migrate on-premise MongoDB instances to the cloud.
MongoDB Atlas also embeds powerful capabilities like:
- MongoDB Atlas Search (powered by the Lucene search engine),
- MongoDB Realm for serverless programming to support mobile applications, and
- MongoDB Atlas Data Lake, which allows object storage to become part of a database.
Advantages of MongoDB Atlas
- Global clusters for world-class applications: Using MongoDB Atlas, we are free to choose the cloud partner and ecosystem that fit our business strategy.
- Secure for sensitive data: It offers built-in security controls for all our data. It enables enterprise-grade features to integrate with our existing security protocols and compliance standard.
- Designed for developer productivity: MongoDB Atlas moves faster with general tools to work with our data and a platform of services that makes it easy to build, secure, and extend applications that run on MongoDB.
- Reliable for mission-critical workload: It is built with distributed fault tolerance and automated data recovery.
- Built for optimal performance: It makes it easy to scale our databases in any direction. We can get more out of our existing resources with performance optimization tools and real-time visibility into database metrics.
- Managed for operational efficiency: It comes with built-in operational best practices, so we can focus on delivering business value and accelerating application development instead of managing databases.
MongoDB Clusters
In the context of MongoDB, “cluster” is the word usually used for either a replica set or a sharded cluster. A replica set is the replication of a group of MongoDB servers that hold copies of the same data; this is a fundamental property for production deployments as it ensures high availability and redundancy, which are crucial features to have in place in case of failovers and planned maintenance periods.
A sharded cluster is also commonly known as horizontal scaling, where data is distributed across many servers.
The main purpose of sharded MongoDB is to scale reads and writes along multiple shards.
What is MongoDB Atlas Cluster?
MongoDB Atlas Cluster is a NoSQL Database-as-a-Service offering in the public cloud (available in Microsoft Azure, Google Cloud Platform, Amazon Web Services). This is a managed MongoDB service, and with just a few clicks, you can set up a working MongoDB cluster, accessible from your favorite web browser.
You don’t need to install any software on your workstation as you can connect to MongoDB directly from the web user interface as well as inspect, query, and visualize data.

Join FAUN: Website 💻|Podcast 🎙️|Twitter 🐦|Facebook 👥|Instagram 📷|Facebook Group 🗣️|Linkedin Group 💬| Slack 📱|Cloud Native News 📰|More.
If this post was helpful, please click the clap 👏 button below a few times to show your support for the author 👇

