Writing Clean Code — Part 4
Making life easier by writing easily readable code
In the last post we saw how the idea of a function doing “ONE thing” is linked to another concept: The levels of abstraction that the various operations in a function have. Let’s now discuss in detail what it actually means by the term “Levels of abstraction in a function”.

Level Of Abstraction
To state in the words of OOP, abstraction typically means,
Showing only the essential information and hiding the unimportant and non-essential information from the outside world.
You might start to think about how it applies in the world of clean functions. Let me explain that. So, in the context of a function, abstraction is nothing but the level of interpretation needed to understand what a statement is doing — the effort taken to interpret what a single line or multiple lines of code do.
Based on this, we have low and high levels of abstraction in a function. To understand better, consider the same 2 examples stated previously:

The first snippet has multiple lines, where each line needs deeper interpretation (ideally it won’t be this simple) to understand what it actually means. We have multiple such lines grouped together in the function. This is a low level of abstraction, since there is nothing hidden, and all the intrinsic details to understand the working are provided explicitly.
Now consider the second snippet, here we have three function calls. Each function name is already clearly stating what its purpose is and the kind of operation done by it. So there is no room for interpretation and not much of an effort is required. All the implementation details and non-trivial information are hidden. Hence there is a high level of abstraction used.
I’ve already mentioned that a function should do only “ONE” thing. This “ONE” thing means that all the operations it deals with should have the same levels of abstraction.
Now, the second snippet completely uses high levels of abstraction and makes it much easier to read and understand, and it would also apply for the individual functions inside.
But in the first snippet, we have multiple functionalities that can be split into individual functions, present inside the same function which hence results in a highly loaded function.
Hence, the second function is relatively cleaner, and easy to read and understand.
Also, it is implied that we cannot mix different levels of abstraction in the same function, which only confuses us more. Even if there are such situations, outsource the low levels into individual functions.
Splitting functions sensibly is a skill by itself.
Rules of thumb for splitting functions
- Extract out code as a function that is closely related or working around the same functionality.
- Extract out code as a function that requires more interpretation than the surrounding code.
Remember these golden rules ever !!
When we go about splitting our functions, it also increases the reusability of that particular function. In turn, we start to follow the principle of DRY (Don’t Repeat Yourself). But also don’t split unnecessarily, just for the sake of taking out code and putting them as separate functions.
Do so, only when the above rules apply.
In addition, beware of splitting functions too much, as this could lead to just renaming an operation. For example: just taking out the return statement and creating a function insensibly for it.
Or, when you cannot find a proper reasonable name for the new function — and it takes much longer than the old code to understand.
Avoid unexpected side effects
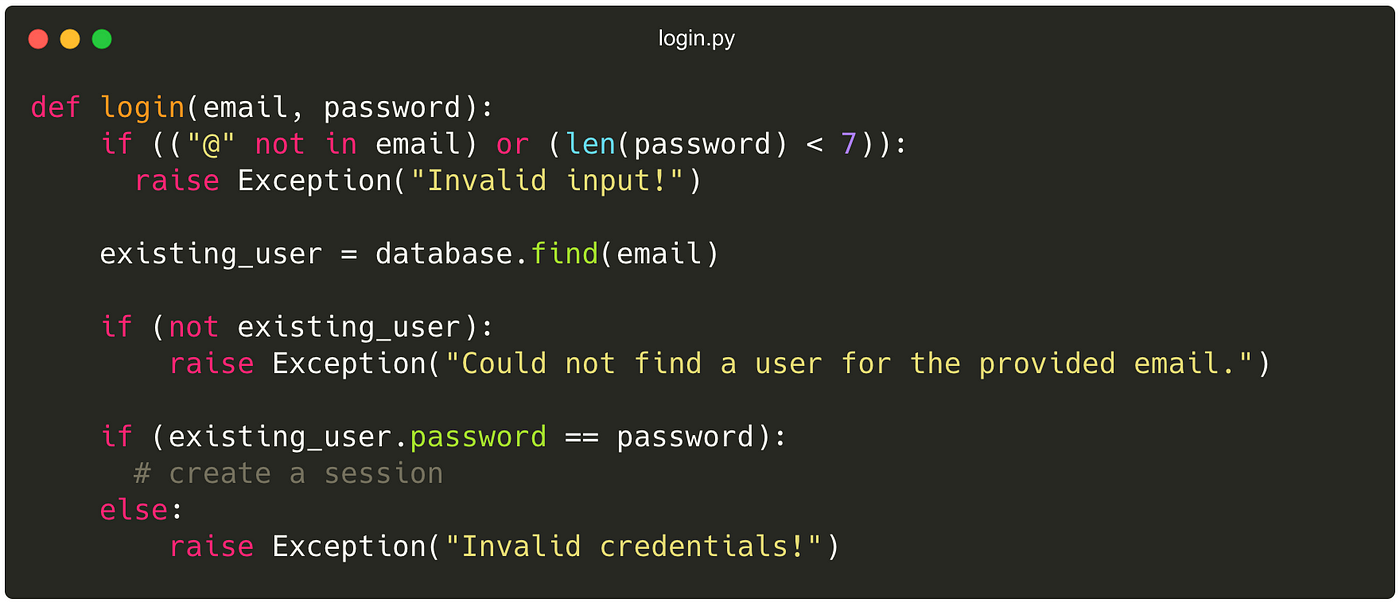
In addition to all the above points discussed, also make sure your function does not have any unexpected side effects. A side effect is an operation that not only operates on the function inputs and gives outputs but also changes the state of the overall system. For example:

In the above snippet, we expect the function to only validate the given inputs, based on defined conditions, but it also creates an unexpected side effect! We don’t usually expect such a function to create a session — at least the function name doesn’t suggest it. Thus, doing so is bad.
Side effects are not always bad. But unexpected side effects are.
When we know a function is going to do something which alters the state of the system, that is fine. It makes it easy for someone who’s going to use that function again. The name of the function by itself would give a sense of understanding how it’s going to give some consequences and let them handle it appropriately.
But when unexpected consequences are produced and not handled properly, it might even bring the entire system down. So be careful about such side effects produced by the function.
If you want to produce such a side effect, then probably you can create a separate function for that and use it. Or, you can rename the existing function to give a better understanding of what it is doing.
Testing your application is a very important part of the software development cycle. If you can’t properly unit test your functions, then it also means your functions are badly written — either there are more functionalities combined in a single function or it is producing unexpected side effects.
I believe you’ve got a better understanding of how to write clean functions now. The key takeaways from this article would be:
- Consider splitting of functions, but be sensible.
- Increases reusability and make code DRY.
- Try not to mix different levels of abstraction in the function.
- Avoid unexpected side effects.
- Check if your function makes unit testing easier.

So the next time when you write functions, try to follow what you’ve learnt so far, and let’s help each other by writing clean code.
Thanks for reading this! Hope you found this useful. Please don’t forget to share your feedback and comments.

Join FAUN: Website 💻|Podcast 🎙️|Twitter 🐦|Facebook 👥|Instagram 📷|Facebook Group 🗣️|Linkedin Group 💬| Slack 📱|Cloud Native News 📰|More.
If this post was helpful, please click the clap 👏 button below a few times to show your support for the author 👇

